我的简陋版任务调度系统后端部分总算调通了,功能包括配置按照一定频率执行和立即执行两种,且配置相当简单:首先在spring启动文件中添加指定注解配置client开启的端口号,然后在方法上添加注解,最后在提供的页面上配置调度服务器地址即可。然后就可以轻松实现任务的自动调度。
进程间通信
做分布式调度不可避免地要用到进程间通信。hot-deploy由于只需要client端向server端通信,所以之前的实现采用了在server端配置servlet的做法。但任务调度系统需要client端和server端做双向通信:client向server通知注册的job信息,server端向client发送job的调度请求。
使用servlet的方式,需要在client端配置servlet类信息,为了最大程度减少client端的配置,我最后采用了netty来做client和server端之间的通信
netty包括server和client,其中Server需要配置绑定的IP地址和开放端口号,而client作为请求发送者,需要对要发送的服务器地址和端口号做配置
原理和实际编码之间是有距离的,我在开发中遇到的问题有:
- 添加的Encoder和Decoder没有起到作用
- server端无法接收到请求
这两个问题都是由于Encoder和Decoder配置不正确导致的。
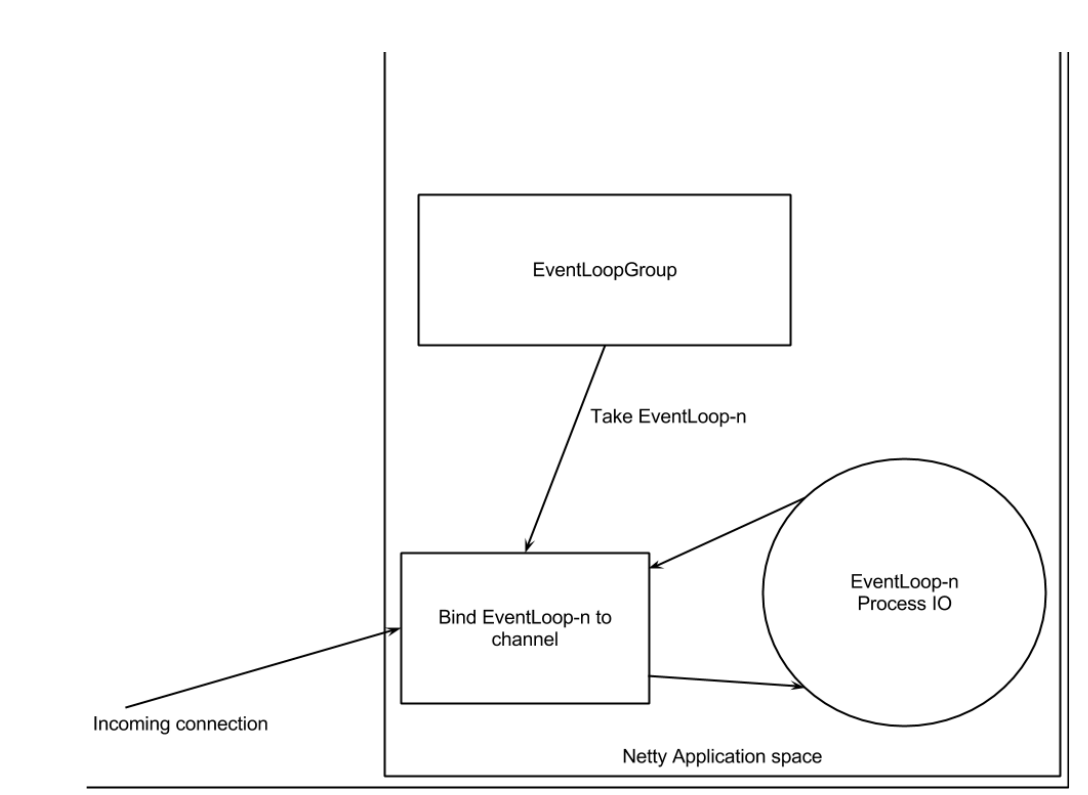
解决这个问题需要先了解下channelHandler相关的东西。netty是非阻塞io通信框架,每当一个channel注册时,Netty会把这个channel和一个EventLoop绑定起来,一个event到达channel后,和channel绑定的channelPipeline中的各个ChannelHandler会按照添加顺序处理这个event事件
//client
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addFirst(new JobScheduleInvoker(jobInfo));
ch.pipeline().addLast(new DataEncoder());
}
});
channel = b.connect(host, port).sync().channel();
channel.closeFuture().sync();
//server
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(group)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {//处理每一个connection
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addFirst(new DataDecoder());
ch.pipeline().addLast(new JobInfoReceiver());
}
});
ChannelFuture f = serverBootstrap.bind(host, port).sync();//创建一个channel并和这个channel绑定
f.channel().closeFuture().sync();
其中JobScheduleInvoker和DataEncoder都是OutboundHandler,DataDecoder和JobInfoReceiver是InboundHandler。client端负责发送数据,channel绑定的channelPipeline,先通过OutboundHandler处理,然后由Inboundhandler处理,根据添加顺序,event的处理顺序为JobScheduleInvoker->DataEncoder->网络传输->DataDecoder->JobInfoReceiver.数据在网络中通过字节码进行传输,所以两端需要通过完成byte和String之间的转换,然后再做相应的逻辑处理。所以一旦添加的顺序出错,发送和接收就会出现问题。
tips
jar
通过jar命令打jar包:jar vf jarName.jar 通过jar命令查看jar包中包含的文件信息:jar tf jarName.jar
classpath*和classpath
首先classpath是指WEB-INF文件夹下的classes目录,当使用classpath时,加载资源时,会从所在jar包的WEB-INF文件夹下的classes目录下查找资源文件;而classpath则会查找所有jar包中的资源文件。 用classpath:需要遍历所有的classpath,所以加载效率会比较差一些,如果只使用classpath:,需要规划好资源文件的路径,尽量避免重名,导致资源文件加载不到的问题。
获取bean
RootBeanDefinition applicationLoader = new RootBeanDefinition(ApplicationLoader.class);
parserContext.getRegistry().registerBeanDefinition(QSCHEDULE_ANNOTATION, applicationLoader); //通过这种方式在spring启动时生成ApplicationLoader的bean实例
public class ApplicationLoader implements ApplicationContextAware {
private static ApplicationContext applicationContext;
public static <T> T getBean(String beanName) {
return (T) applicationContext.getBean(beanName);
}
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationLoader.applicationContext = applicationContext;
}
}
开发中出现的问题:applicationContext为null。问题解决:在系统启动的时候,调用了getBean方法,但此时spring的bean加载和初始化尚未完成,导致在调用getBean方法时无法获取到资源锁,从而阻塞线程,后续sping的加载过程被也被中断。解决这个问题的方法就是把getBean方法的调用放入到新线程中去执行,这样spring的加载过程得以继续进行,当初始化完成,getBean便可以获得返回结果。 另外netty的server启动也会阻塞线程,需要放入到新线程中启动,否则也会导致系统启动时,阻塞spring的加载过程
阿里之ScheduleX
在开发过程中,了解到阿里也做了一个付费版调度系统,简单通过使用文档,大概了解了下阿里的ScheduleX实现方案。
- 创建定时任务处理器 第一部分创建定时任务处理器介绍了client端的配置,包括添加jar包和添加调度任务类
public class ExecuteShellJobProcessor implements ScxSimpleJobProcessor {
public ProcessResult process(ScxSimpleJobContext context) {
System.out.println("Hello World! "+new Date());
return new ProcessResult(true);//true表示执行成功,false表示失败
}
}
所有调度任务类实现了ScxSimpleJobProcessor的process接口 添加client配置:
<bean id="schedulerXClient" class="com.alibaba.edas.schedulerX.SchedulerXClient" init-method="init">
<property name="groupId">
<value>101-1-1-77</value>
</property>
<property name="regionName">
<value>cn-hangzhou</value>
</property>
<!--如果使用的是上海Region集群,需要设置domainName属性,同时指定RegionName为cn-shanghai
<property name="regionName">
<value>cn-shanghai</value>
</property>
<property name="domainName">
<value>schedulerx-shanghai.console.aliyun.com</value>
</property>-->
</bean>
另外有java应用方式启动的
SchedulerXClient schedulerXClient = new SchedulerXClient();
schedulerXClient.setGroupId("101-1-1-52");
schedulerXClient.setRegionName("cn-hangzhou");
/*
//如果使用的是上海Region集群,需要设置domainName属性,同时指定RegionName为cn-shanghai
schedulerXClient.setRegionName("cn-shanghai");
schedulerXClient.setDomainName("schedulerx-shanghai.console.aliyun.com");
*/
try {
schedulerXClient.init();
} catch (Throwable e) {
e.printStackTrace();
}
}
可以在client端需要做的配置有groupid和regionname,client启动方法为init()
-
代码完成后,在web页面做配置
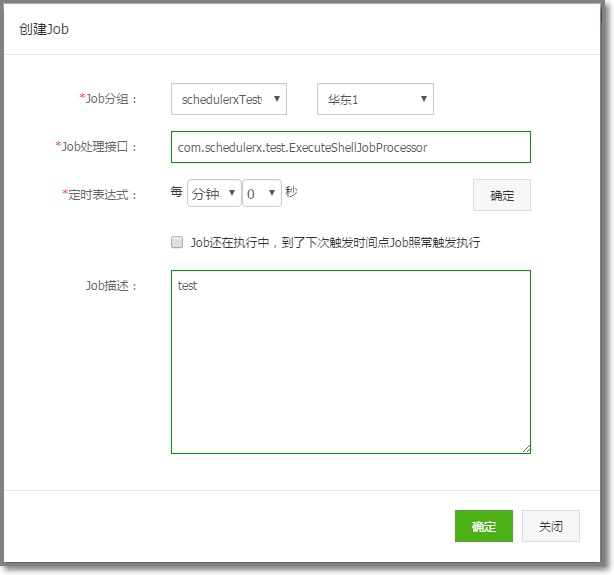 在页面上需要配置执行任务的接口名称
在页面上需要配置执行任务的接口名称 -
总结 没看源代码,只从配置来说,可以看到scheduleX是通过页面手工添加任务调度类,这样避免了client向server端的通信。但是如果能通过client端将Job的相关信息发送到server端的话,就可以免去这个配置的过程。 groupId应该是为了做分布式调度的,之前的考虑是把所有应用相关的机器地址放在远程,每次调度的时候从zookeeper中动态获取当前可用的服务地址