基本操作
参考:http://kafka.apache.org/quickstart#quickstart_multibroker
kakfa安装配置启动
http://kafka.apache.org/quickstart
- 启动zookerper
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka$ ./bin/zookeeper-server-start.sh config/zookeeper.properties
- 启动kafka
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ ./bin/kafka-server-start.sh config/server.properties
server.properties中的cluster_id要求唯一
- 创建主题:
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
Created topic “test”.
- 启动producer
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ ./bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
- 启动consumer
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ ./bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test –from-beginning
在Producer终端输入字符串,在Consumer终端将会接收到Producer端收到的信息
查看主题相关信息
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ ./bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3 –partitions 1 –topic my-replicated-topic
查看:
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ ./bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
每一行代表一个分区
leader:负责指定分区的所有读写操作的节点(cluster_id=2的节点)
replicas:对指定分区做日志复制的节点列表(cluster_id =2,0,1的节点)
isr:当前可用的或可成为leader的复制列表的子集(cluster_id =2,0,1的节点)
kafka设置多个集群
- 设置新集群的配置文件
cp config/server.properties config/server-1.properties
修改以下配置:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
- 启动
bin/kafka-server-start.sh config/server-1.properties
数据的导入
- 设置连接
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
- 启动consumer监听指定主题
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic connect-test –from-beginning
- 文件输入
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ echo “line”»test.txt
connect-file-source.properties文件中设置了数据导入来源,connect-file-sink.properties 设置了数据保存地址
数据处理
- 新建主题
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic streams-file-input
- 设置从文件中获取producer输入
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-console-producer.sh –broker-list localhost:9092 –topic streams-file-input < file-input.txt
- 新建应用
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ vi org.apache.kafka.streams.examples.wordcount.WordCountDemo
- 运行应用
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
- 消费
jinyan@jinyan-latitude-e7470:~/Documents/applications/kafka_2.12-0.10.2.1$ bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic streams-wordcount-output –from-beginning –formatter kafka.tools.DefaultMessageFormatter –property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer –property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer –property print.key=true
all 1 lead 1 to 1 hello 1 streams 2 join 1 kafka 3 summit 1
流处理是对发送的消息进行再次处理
java开发
参考:http://kafka.apache.org/documentation
- 添加依赖
<!--kafka-->
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka_2.10 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.10.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.10.2.1</version>
</dependency>
<!--kafka-->
stream
- 添加Producer和Consumer,并新建Stream要处理的消息主题
- 新建KafkaStreams对象
- 在Producer端发送消息,启动KafkaStreams运行
KStream的相关用法
- 针对每条消息记录进行处理:
//KStream示例
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount1");//一个stream应用指定一个topic
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// setting offset reset to earliest so that we can re-run the demo code with the same pre-loaded data
// Note: To re-run the demo, you need to use the offset reset tool:
// https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Application+Reset+Tool
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> source = builder.stream("topic1");//input topic
processMessage(source);
KafkaStreams streams = new KafkaStreams(builder, props);
streams.start();
}
private static void processMessage(KStream<String, String> source) throws FileNotFoundException {
final PrintWriter printWriter = new PrintWriter(WordCountDemo.class.getResource("").getPath() + "outputfile");
source.foreach(new ForeachAction<String, String>() {
@Override
public void apply(String key, String value) {
printWriter.append("|").append(key).append("|").append(" ").append("|").append(value).append("|").append("\n");
printWriter.flush();
}
});
source.print();//打印到控制台
source.writeAsText(WordCountDemo.class.getResource("").getPath() + "outputfile");//写入文件
}
kafka用途
参考:http://kafka.apache.org/uses#uses_commitlog
- 消息处理
- 网站实时监测
- 监控
- 日志收集
- 数据流处理
- 事件跟踪(存在事件顺序)
- 分布式系统的提交记录
源代码编译
- 下载源码
git clone http://git-wip-us.apache.org/repos/asf/kafka.git
-
gradle编译
- cd
- gradle idea
document
kafka集群中消息时根据设置的过期时间来保存的,即使消息未消费,过了过期时间也会被删除.而对消息的处理效率不会因为存储消息的大小而降低.
每个consumer会单独保存读取消息的位置,并且可根据需要自己重置读取的位置
kafka是如何实现高吞吐的?
kafka在接收到Producer发送的消息之后,首先将消息保存再磁盘上,再进行后续处理.
- 顺序读写
磁盘在进行读写的时候,相对于涉及磁盘磁头寻道的读写,顺序读写只需要很少的扇区旋转时间.kafka的消息是顺序写入的,保证了消息的读写速度.
- 零拷贝
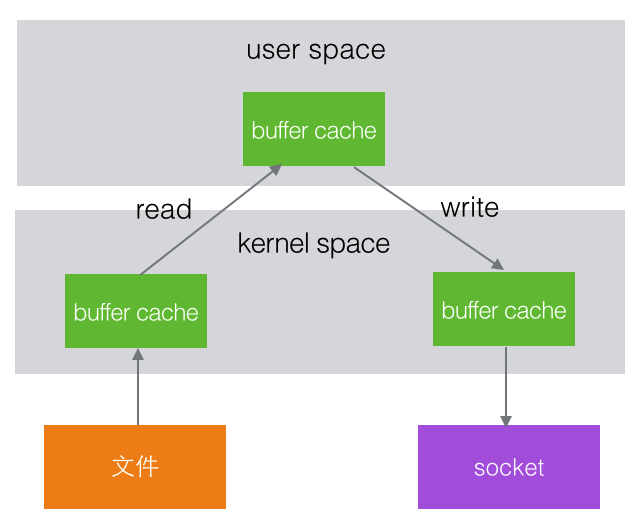
在操作系统内部,文件和socket属于硬件资源,程序运行是在user space,这之间有一个kernel space.文件的读写过程为:首先从文件中读取数据到kernel space中的缓冲区中,然后读取到user space的缓冲区,再写入到kernel space的缓冲区,最后写入文件或网络中.
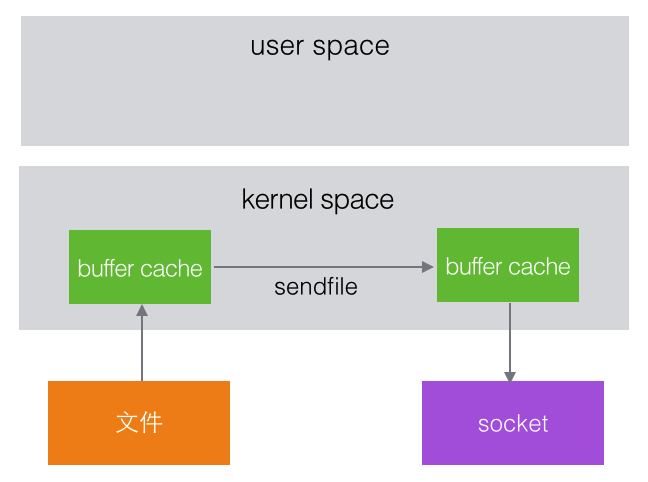
在Linux kernel 2.2之后,出现了一种叫做”零拷贝”的系统调用机制,数据不需要再拷贝到 user space的缓冲区
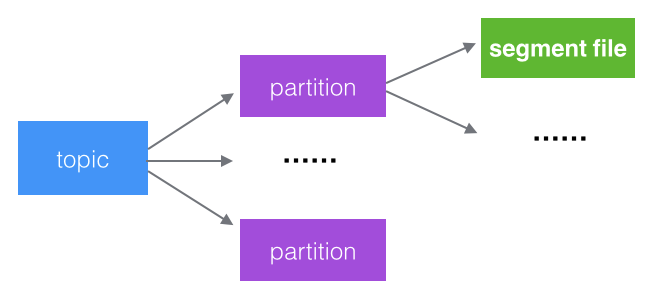
- 文件分段
kafka的一个topic队列消息被分成了多个partition,每个partition又有多个segment,每次文件操作都是对一个小文件的操作,操作轻便,并且增加了并行处理能力
- 批量发送
kafka允许消息批量发送,即先将消息缓存在内存中,再批量发送出去,减少了服务端的I/O次数.
- 数据压缩
Producer发送的消息可以压缩后发送,减少了网络传输的压力
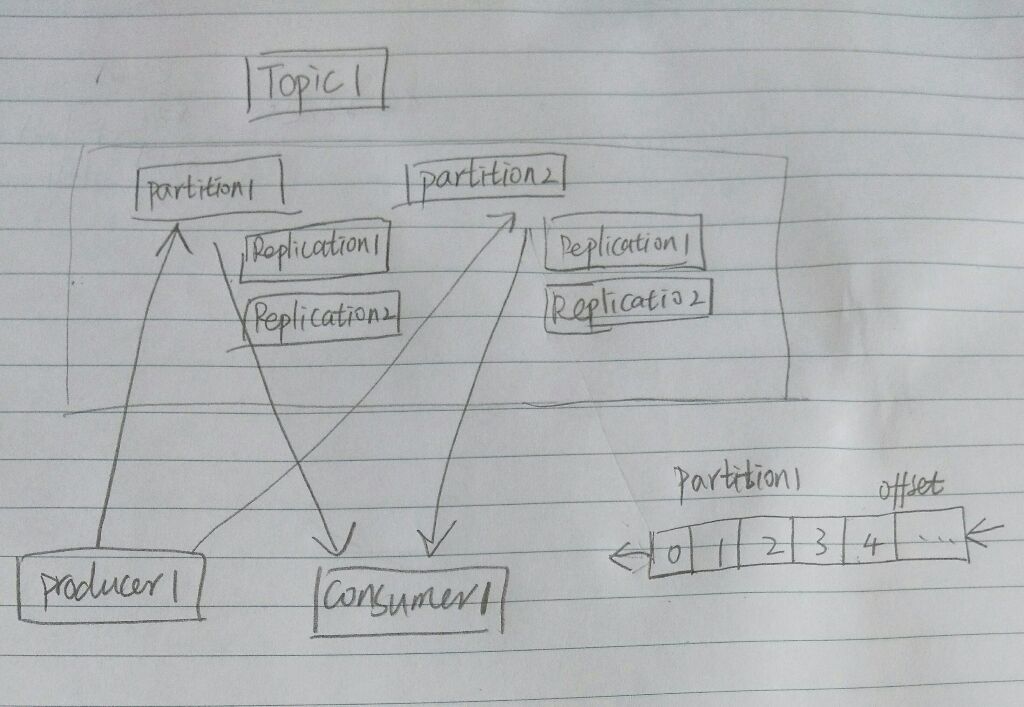
kafka的系统架构
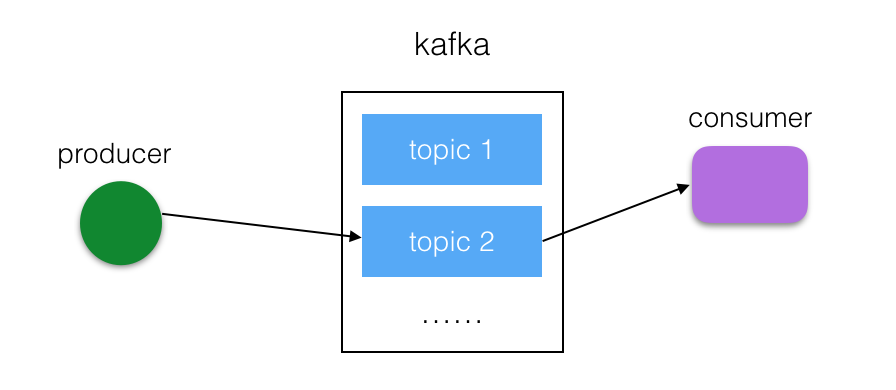
Producer向kafka集群发送消息,kafka将消息保存到本地磁盘,并将指定topic发送给订阅的consumer群组.
每个topic可设定多个partition,每个partition会被均匀复制到不同的服务器中(Replications),每个partition会包含leader和follower,其中,leader负责读写请求,follower负责容灾,当leader出现问题的时候,会从follower中选举出一个leader.
producer向主题中写入消息,其实就是向某个partition写入,具体向哪个partition写入由producer决定,消息写入partition的方式是顺序追加,为每条消息设置一个offset.
consumer群组中包含一个或多个消费者,一个consumer群组订阅一个topic,当topic中产生新消息时会被发送到consumer群组中的某个consumer中,consumer负责维护读取消息的位置